L'extension pgvector
 2025-01-17
2025-01-17
 1884 mots, 9 minutes de lecture
1884 mots, 9 minutes de lecture
 Philippe Viegas
Philippe Viegas
 2025-01-17
1884 mots, 9 minutes de lecture
Philippe Viegas
2025-01-17
1884 mots, 9 minutes de lecture
Philippe Viegas
Ces deux dernières années, on aura noté l’engouement autour de l’IA, du machine learning et de son accessibilité via les
plateformes telles que OpenAI. La communauté PostgreSQL s’est penchée dessus aussi afin de rendre PostgreSQL attractif
comme moteur de bases de données vectorielles, grâce à son extensibilité, notamment depuis la sortie de l’extension pg_vector.
L’extension pgvector créée par Andrew Kane, et initiée en avril 2021, vient de connaître un élan de popularité depuis deux ans, surtout à la vue de l’engouement des travaux autour de l’IA et du machine learning, et de fait des vecteurs.
Pourtant les principes mathématiques et les algorithmes utilisés dans le machine learning et l’IA existent depuis plusieurs décennies. Ce qui a changé c’est l’accessibilité de ces derniers et la mise à disposition des données issues de ces algorithmes très rapidement, ce qui implique de pouvoir stocker les données vectorielles au plus près des applications.
Pour revenir à pgvector, cette extension permet à PostgreSQL de stocker des données vectorielles grâce à un nouveau type de données spécialisé et indexable, et d’effectuer des recherches vectorielles de type K-NN (K nearest-neighbor) ou ANN (aproximate nearest-neighbor) en proposant désormais deux types d’index : IVFFlat et HNSW.
Jonathan Katz a écrit une série d’articles sur pgvector, auquel il contribue activement, et notamment cet article : Vectors are the new JSON in PostgreSQL où il y fait le parallèle entre le support du JSON par PostgreSQL et les vecteurs. Jonathan Katz nous rappelle comment PostgreSQL a fait le pari de supporter le format JSON/JSONB, à la base un format d’échange, pour répondre aux besoins des développeurs d’applications afin de stocker des données au format JSON et de pouvoir les requêter efficacement.
La communauté PostgreSQL continue d’ailleurs d’implémenter le standard SQL/JSON et pousse à son adoption. La version 17 de PostgreSQL fournit par exemple de nouvelles fonctions JSON et un nouveau constructeur JSON_TABLE().
Ce qui s’est passé pour PostgreSQL avec JSON est en train de se reproduire avec les vecteurs : le besoin de stocker et rechercher des vecteurs, donnant l’occasion à PostgreSQL de devenir une base de données vectorielles avec toutes les fonctionnalités que PostgreSQL offre déjà.
Une des forces de PostgreSQL est son extensibilité éprouvée et permet d’ajouter de nouvelles fonctionnalités sans toucher au code principal. L’écosystème des extensions est immense.
Vous pouvez retrouver une liste exhaustive des extensions sur PGXN. Parmi les plus connues, on peut citer pg_stat_statements pour surveiller les statistiques d’exécution des requêtes SQL, postgis pour gérer les données géospatiales ou encore timescaledb pour gérer les séries temporelles.
Parmi les vues disponibles sous PostgreSQL pour lister les extensions, vous pouvez utiliser les vues pg_available_extensions ou pg_available_extension_versions, ou la vue pg_extension.
Avant de rentrer dans le détail de l’implémentation de pgvector, nous allons rappeler ce qu’on entend par bases de données vectorielles.
Une base de données vectorielles doit permettre de stocker des vecteurs et rechercher des similarités de manière efficace et précise dans un espace vectoriel à haute dimension, en offrant une indexation performante et des opérations de calcul de distance adaptées selon le cas d’usage envisagé.
Les cas d’usage de ces bases de données pouvant être les suivants :
Une base de données vectorielles doit également apporter les fonctionnalités attendues sur les bases de données relationnelles telles que les transactions, la sécurité, la scalabilité, la haute disponibilité et la recherche hybride.
Les vecteurs produits par plongement vectorielle (embeddings) par les grands modèles de langage (LLM) sont des tableaux de données numériques (réels à virgule flottante, type real stocké sous 4 octects) permettant de représenter des données hétérogènes comme des images, des fichiers audios ou des textes.
[-0.07, -0.53, -0.02, …, -0.61, 0.59]
Les vecteurs sont de dimension finie dont le nombre varie selon les modèles ayant produits ces derniers. Par exemple, le modèle text-embedding-3-small de chez OpenAI produit des vecteurs de 1356 dimensions, alors que le modèle text-embedding-0004 de chez Google est à 768 dimensions. Chaque modèle définit également les types d’opérations de distance acceptées.
pgvectorL’extension pgvector initié par Andrew Kane permet d’apporter à PostgreSQL le stockage et la recherche d’un nouveau type de données, le type vector à n dimensions. Il est possible d’utiliser la recherche exact et approximative (ANN).
Par défaut, le type vector utilise le type real sous quatre octets pour le stockage, mais il est possible de réduire la taille de stockage en utilisant des vecteurs de demi précision, des binaires ou le type sparse.
Pour comparer les vecteurs entre eux et faire des recherches de similarité, l’extension implémente plusieurs type d’opérations de distance en fonction de la nature des données et de l’objectif de la comparaison. On compte pas moins de six opérateurs de distance, les deux derniers opérateurs étant réservés au type vecteur binaire :
<-> distance L2 ou Euclidienne (vector_l2_ops)<#> produit scalaire (vector_ip_ops)<=> distance cosinus (vector_cosine_ops)<+> distance L1 ou Manhattan (vector_l1_ops)<~> distance Hamming (bit_hamming_ops)<%> distance Jaccard (bit_jaccard_ops)L’extension prend en charge également de nombreux langages existants pour les clients PostgreSQL.
Pour démarrer, créons une table avec une colonne de type vecteur (à trois dimensions pour l’exemple), insérons des données et effectuons une recherche de similarité de documents selon la distance Euclidienne (ou L2) avec l’opérateur <-> :
CREATE TABLE documents (
id serial PRIMARY KEY,
embedding vector(3)
);
INSERT INTO documents (embedding) VALUES ('[1,2,3]'), ('[4,5,6]');
SELECT * FROM documents ORDER BY embedding <-> '[3,1,2]' LIMIT 5;
L’extension propose deux types de vecteurs pour la recherche aproximative (ANN) : IVFFlat et HNSW, en plus de la recherche exacte (recherche séquentielle). Le choix de l’un des types d’index est un compromis à faire entre
performance et rappel. La performance étant entendue aussi bien en termes de construction de l’index que de recherche via cet index. Le rappel mesure quant à lui le ratio entre les éléments pertinents retournés parmi tous les éléments pertinents.
Il est aussi possible de jouer avec les différents paramètres des index afin de placer le curseur selon votre cas d’usage.
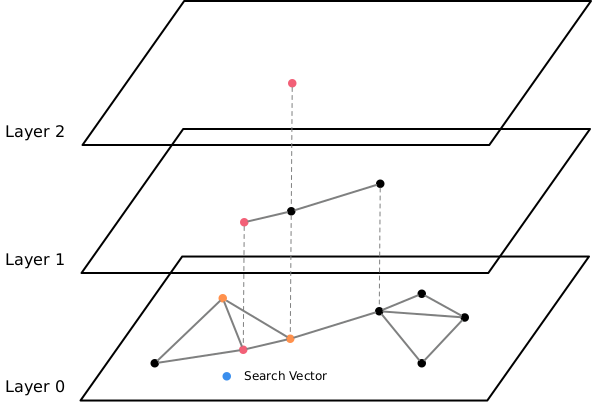
Le premier index disponible est l’index HNSW, pour Hierarchical Navigable Small World. Cet index est basé sur un graphe multi-couches, chaque couche étant plus ou moins dense. Plus on descend dans les couches, plus il y a de vecteurs.
Pour effectuer une recherche ANN, il suffira de traverser le graphe à la recherche de la plus courte distance entre les vecteurs cibles.
 © Github @ skyzh
© Github @ skyzh
La création de l’index HNSW peut se faire sans aucune données présentes initialement. Le temps de construction de l’index sera plus long et utilisera plus de mémoire que l’index IFVFlat, mais sera plus performant lors des requêtes. Il faudra créer un index par type d’opérateur de distance.
L’index possède deux paramètres lors de la construction de ce dernier :
m (par défaut à 16) nombre de connexions entre vecteurs, par coucheef_construction (par défaut à 64) nombre de vecteurs candidats par voisinage pour la construction du graphePar exemple :
CREATE INDEX ON documents USING hnsw (embedding vector_cosine_ops) WITH (m = 16, ef_construction = 100);
En augmentant ces paramètres, il est possible d’améliorer la valeur de rappel mais au détriment du temps de construction de l’index et de la mémoire utilisée. Il est aussi possible d’affiner la recherche avec le paramètre ef_search, mais au détriment de la vitesse de requête :
ef_search (défaut à 40) nombre de vecteurs candidats par voisinage pour requêteSET hnsw.ef_search = 100;
SELECT * FROM documents ORDER BY embedding <=> '[3,1,2]' LIMIT 10;
Il est possible également d’accélérer la création de l’index s’il peut contenir dans la taille définie par le paramètre maintenance_work_mem mais faire attention dans ce cas à ne pas consommer toute la mémoire disponible. On peut enfin rajouter des workers supplémentaires avec max_parallel_maintenance_workers et max_parallel_workers pour accélérer aussi la construction de l’index.
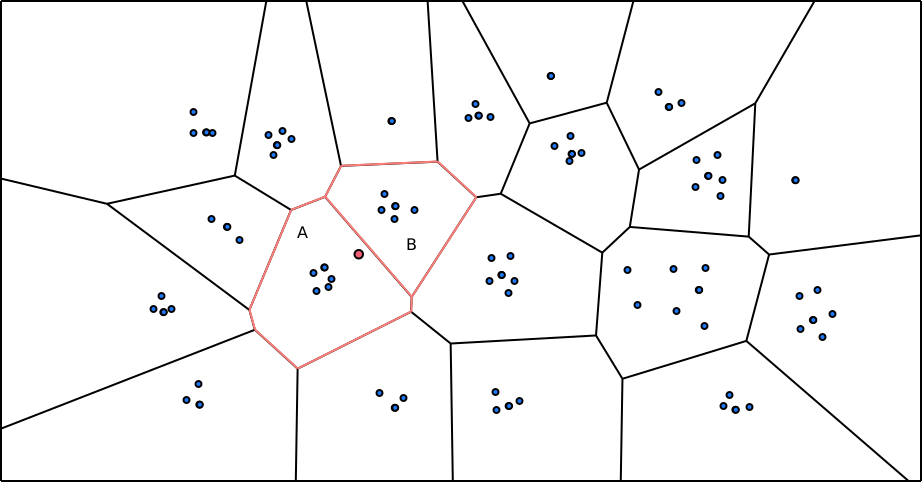
Le deuxième index est l’index IVFFlat qui se base sur la création de liste (clusters) de vecteurs, et recherche un sous-ensemble de ces listes le plus proche du vecteur cible (avec l’algorithme K-means pour la recherche de centroïde). La construction de l’index ne peut se faire qu’après avoir inséré vos données. Cet index utilise moins de mémoire et est plus rapide à la construction que l’index HNSW mais est moins performant que ce dernier, en terme de vitesse et rappel.
 © Github @ skyzh
© Github @ skyzh
Il est aussi important de noter que si la distribution des vecteurs change fréquemment, il sera nécessaire de reconstruire l’index (REINDEX CONCURRENTLY).
L’index IVFFlat dispose d’un paramètre pour la construction :
lists nombre de listesCREATE INDEX ON documents
USING ivfflat (embedding vector_cosine_ops)
WITH (lists = 100);
Plus le nombre de liste est grand, plus la durée de construction sera longue.
Pour la recherche, il est possible de modifier le paramètre :
probes (1 par défaut) nombre de listes dans lesquelles rechercherSET ivfflat_probes = 2;
SELECT * FROM documents ORDER BY embedding <=> '[3,1,2]' LIMIT 3;
En augmentant le paramètre probes, il est possible d’améliorer le rappel au détriment de la performance. On peut rajouter aussi des workers supplémentaires avec max_parallel_maintenance_workers et maw_parallel_workers pour accélérer aussi la construction de l’index comme avec l’index HNSW.
La version 0.8.0 de pgvector a ajouté la possibilité d’activer le scan d’index itératif (désactivé par défaut). Avec cette fonctionnalité, PostgreSQL va scanner les index approximatifs à la recherche des plus proches voisins, appliquer ensuite les filtres additionnels (clause WHERE) puis scanner à nouveau les index si le nombre de voisins retournés n’est pas suffisant jusqu’à obtenir la valeur attendue.
Il est possible de l’activer pour chaque index, et choisir l’ordre du tri par rapport à la distance entre éléments :
SET hnsw.iterative_scan = strict_order|relaxed_order|off;
SET ivfflat.iterative_scan = relaxed_order|off;
Vous pouvez configurer le nombre d’éléments scannés pour chaque type d’index :
SET hnsw.max_scan_tuples = 20000; (par défaut)
SET ivfflat.max_probes = 100;
Par défaut, pgvector stocke le type vecteur sous 32 bits, en nombre à virgule flottante. Depuis la version 0.7.0, il est possible d’optimiser le stockage des vecteurs et la performance des requêtes en réduisant le nombre de bits utilisés pour stocker les vecteurs, et ainsi réduire la taille des index et donc l’empreinte mémoire et disque. On peut désormais utiliser le type halfvec stocké sous 16 bits et le type binaire bit.
Par exemple :
CREATE INDEX ON documents USING hnsw ((embedding::halfvec(1536)) halfvec_l2_ops);
CREATE INDEX ON documents
USING hnsw ((binary_quantize(embedding)::bit(3072)) bit_hamming_ops);
SELECT id FROM documents
ORDER BY binary_quantize(embedding)::bit(3072) <~> binary_quantize($1)
LIMIT 10;
Le type vecteur halfvec permet de stocker jusqu’à 4096 dimensions lorsque le type vecteur était limité à près de 2000 dimensions et le type binaire pouvant aller jusqu’à 64000 dimensions. L’inconvénient étant la réduction de l’information qui entraîne une diminution du rappel.
Comme vous venez de le voir, PostgreSQL grâce à son extensibilité permet d’adresser différents cas d’usage, et dans cet article l’extension pgvector en est la parfaite illustration tranformant PostgreSQL en une base de données vectorielles tout en fournissant les fonctionnalités de la base de données relationnelles éprouvées depuis de nombreuses années.
pgvector permet de répondre aux besoins issues autour de l’IA et sa popularité ne risque pas de retomber si l’on en croît le dépôt GitHub hébergeant le projet.
Crédits photos : Jerry Kavan



LOXODATA
SÀRL au capital de 380 000 €
RCS Vesoul-Gray B 520 264 896
SIRET 520-264-896 00017
Code APE 6202A
N° TVA Intra Com. FR01520264896
Siège social: 31 rue Maurice Gillot, 70000 Navenne
Téléphone fixe: +33 1 797 2 5775
Directeur de la publication: Stéphane Schildknecht
Hébergeur :
OVH SAS
2 rue Kellermann
59100 Roubaix - France
RCS Lille Métropole 424 761 419 00045